

















[thebell interview]"AI 핵심은 인프라SW…모레, 넥스트 딥시크 만들 것"조강원 대표 "엔비디아 GPU 없이 LLM 개발 가능 증명…'프롬 스크래치' 모델 개발 도전"
최윤신 기자공개 2025-02-25 14:16:38
이 기사는 2025년 02월 21일 14시50분 thebell에 표출된 기사입니다

최근 서울 강남구 본사에서 만난 조강원 모레 대표이사(사진)는 더벨과의 인터뷰에서 이같이 말했다. 모레는 엔비디아가 독점하고 있는 인공지능(AI) 인프라 연산반도체 시장에 균열을 도모하는 기업이다. 엔비디아는 고성능 GPU와 함께 AI연산에 특화된 프로그래밍 소프트웨어 쿠다를 이용해 전세계의 AI 개발자들을 락인시켰다. 모레는 쿠다보다 클러스터링 능력이 뛰어난 소프트웨어 인프라를 제공함으로써 엔비디아의 비싼 칩을 사용하지 않더라도 고도의 연산작업을 수행할 수 있다는 걸 증명해왔다.
모레의 인프라 소프트웨어 세일즈가 본격화할 것으로 전망되는 가운데, LLM분야에서도 새로운 사업을 본격화하고 있다. 글로벌 빅테크의 오픈소스를 이용해 능력을 증명했고, 설계부터 시작해 글로벌에서 경쟁할 수 있는 범용 LLM을 만들겠다는 포부를 가지고 있다.
◇국내 첫 슈퍼컴퓨터 '천둥'에서 이어진 창업

모레의 창업 스토리는 천둥의 개발부터 이어진다. 조 대표는 "당시 연구실에 슈퍼컴퓨터가 없었기 때문에 소프트웨어 연구 경쟁력을 갖기 어려웠고 슈퍼컴퓨터를 직접 제작하고 나섰다"며 "다만 당시에도 슈퍼컴퓨터에 필요한 엔비디아의 고성능 GPU는 비싸 학교의 연구비용으로 감당할 수 있는 수준이 아니었다"고 회상했다.
수백억원에 달하는 슈퍼컴퓨터를 싸게 만들기 위해 강구한 방법이 일반 PC에 들어가는 GPU를 연결해 사용하는 것이었다. 슈퍼컴퓨터의 기본 단위인 '노드(node)'당 2개의 GPU가 들어가는 상식을 깨고 4개의 GPU를 집적해 성능을 끌어올렸다. 전에 없던 구조였기 때문에 연구팀이 직접 쿨링(냉각)부터 네트워크 연결, 소프트웨어 개발까지 완료했다.
이 결과 7억원이라는 저렴한 비용으로 슈퍼컴퓨터를 만들어냈다. 이렇게 만들어진 천둥은 세계 슈퍼컴퓨터 탑 500리스트에서 277위를 차지하며 큰 화제를 모았다. 조 대표는 "277위라는 전체 성능 등수보다 노드 당 성능이 가장 뛰어났다는 점에서 의미가 있었다"고 강조했다.
2020년경 GPU기반 슈퍼컴퓨터를 이용한 거대언어모델(LLM)이 주목받기 시작했다. 소프트웨어 최적화를 통해 저렴한 하드웨어를 가지고 좋은 성능을 내는 데는 자신이 있었던 만큼 이를 AI 영역에 적용해보기로 마음 먹었다. 모레 창업 배경이다.
비싼 엔비디아의 GPU가 아닌 AMD사의 GPU를 기반으로 인프라솔루션을 개발했다. 설립 초기 KT로부터 전략적투자를 유치하며 빠르게 기회를 잡았다. KT와 협력해 AMD GPU를 이용해 초대형 AI클러스터를 구축하는 작업을 진행했다. 현재 모레의 소프트웨어는 KT의 AI 클라우드 서비스에서 '하이퍼스케일 AI컴퓨팅'(HAC)이라는 상품명으로 상용 서비스되고 있다. 현재 100곳이 넘는 고객들이 모레 플랫폼 기반의 HAC를 사용하고 있다.
모레는 엔비디아 쿠다가 제공하는 것과 동일한 풀스택 솔루션을 제공한다. 고도의 병렬화 처리 기법을 통해 대규모 AI모델을 효율적으로 개발하고 학습하도록 돕는다. 실제 AMD사의 GPU와 모레의 소프트웨어가 결합된 AI서버는 성능에 있어서도 엔비디아의 GPU서버와 대등하거나 일부 능가하는 성능을 실현하고 있다는 게 조 대표의 설명이다. 이는 모레의 소프트웨어가 엔비디아의 쿠다보다 클러스터링 능력에서 강점을 보이는 데서 기인한다.
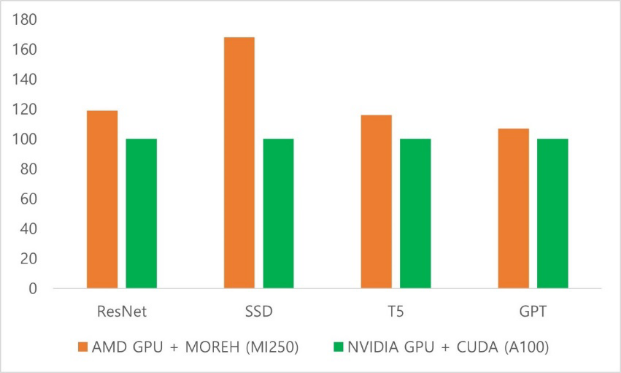
현재 상황에서 클러스터링 능력을 가진 소프트웨어 기술력이 결국 AI 산업의 핵심이라는 게 그의 시각이다. 조 대표는 "LLM을 만들려면 결국 GPU 수백·수천장을 묶어 사용해야 한다"며 "개별 GPU를 사용할 수 있도록 개발된 쿠다는 여기에 있어 한계가 분명하기 때문에 오픈AI와 딥시크는 쿠다를 대체하는 자신만의 소프트웨어를 개발해 사용하고 있고, 이를 통해 차별화된 경쟁력을 만들고 있다"고 설명했다.
글로벌 AI 반도체 기업들이 모레에 주목하는 것도 이 때문이다. 미국 AMD 본사는 2023년 모레의 시리즈B 라운드에 KT와 함께 전략적 투자자로 참여했다. 당시 포레스트파트너스, 스마일게이트인베스트먼트가 재무적 투자자로 참여했다. 지난해 11월에는 미국의 AI칩 개발사인 텐스토렌트가 모레와 AI 데이터센터 솔루션 사업화 본격 추진을 위한 전략적 파트너십 양해각서(MOU)를 체결하기도 했다. 텐스토렌트는 세계적인 반도체 프로세서 전문가 짐 켈러(Jim Keller)가 이끄는 AI반도체 회사다.
조 대표는 모레의 세일즈 실적이 올해부터 본격화 할 것이라고 자신했다. 그는 "지난해부터 아시아를 중심으로 글로벌 고객사에 본격적으로 세일즈를 하고 있다"며 "다수의 PoC(개념검증)를 성공적으로 끝냈고, 이 중 몇 곳에서 구체적인 도입논의가 진행되고 있다"고 설명했다.

◇자회사로 별도 사업화…"글로벌 경쟁력 가진 모델 만들 것"
모레는 AI 인프라뿐만 아니라 LLM을 개발하는 프로젝트도 진행 중이다. 처음 LLM 모델을 만들기 시작한 것은 엔비디아의 GPU와 쿠다를 이용하지 않더라도 LLM을 만들 수 있다는 것을 증명하기 위해서였다.
조 대표는 "고객들에게 AMD GPU 기반으로 우리 소프트웨어를 활용하면 LLM을 만들 수 있다는 것을 증명하기 위해 시작했다"며 "기존의 모델들을 우리 인프라에서 학습시켰을 때 엔비디아 GPU로 학습시킨 것과 동일한 결과가 나온다는 것을 보여주는 게 최초의 목적이었다"고 회상했다.
처음 개발한 모모(MoMo)-70B 모델은 2024년 1월 세계 최대 머신러닝 플랫폼 허깅페이스에서 운영하는 ‘오픈 LLM 리더보드’ 평가에서 1위에 오르며 가능성을 보여줬다. 석사를 갓 졸업한 인력과 학사를 갓 졸업한 인력이 알리바바의 큐원 모델을 기반으로 파인튜닝(추가학습)해 만든 모델이다.
조 대표는 "리더보드 평가 1위가 상업적 의미를 가지는 것은 아니다"라면서도 "이전에 LLM 개발 경험이 없는 인력 단 2명이서 3개월만에 이런 모델을 만들어 냈다는 게 의미가 있었다"고 평가했다.
이런 성과를 기반으로 직접 LLM을 만들어 나가는 사업을 병행하기로 했다. 10명가량으로 구성된 팀을 만들어 본격적으로 LLM 개발에 나섰다. 지난해 12월 자체 개발한 한국어 LLM인 ‘Motif(모티프)-102B’를 허깅페이스에 오픈소스로 공개했다. AMD GPU와 자체 소프트웨어를 가지고 메타의 라마를 기반으로 학습한 모델이다. 한국판 AI 성능 평가 체계인 'KMMLU' 벤치마크에서 오픈AI(59.95점)보다 높은 64.74점을 얻었다.
조 대표는 "내부적으로도 난이도가 높은 벤치마크 테스트를 수행했는데 GPT4와 비슷한 수준이 나왔다"며 "모티프 모델을 기반으로 서비스하는 실제 사업을 추진하고 있어 조만간 실사용 사례가 나올 것"이라고 말했다.
현재 LLM을 별도로 사업화 하기위해 자회사로 분리하는 작업을 진행 중이다. 그는 "모레는 매출이 본격화하면 추가적인 투자유치가 필요하지 않다"며 "LLM 모델은 유의미한 모델을 만들기 위해 지속적인 투자가 필요하기 때문에 별도 법인에서 투자를 유치할 예정"이라고 말했다.
신설되는 법인에서는 라마 등 빅테크가 공개한 오픈소스를 이용하지 않고 처음부터 학습을 시키는 프롬 스크래치(From Scratch) 방식으로 LLM을 만들 예정이다. 조 대표는 "라마를 기반으로 하면 구조를 바꾸더라도 어느정도 정해진 틀에서 갈 수밖에 없는 제약이 있다"며 "모델 설계부터 학습기법들을 모두 만들어 학습을 진행하고 있다"고 말했다.
그는 "한국어에 특화된 것이 아니고 다국어를 지원하며 글로벌 오픈소스 LLM과 직접 경쟁할 수 있을만한 모델, 즉 '넥스트 딥시크'를 만들려고 한다"며 "LLM 모델에서 경쟁력을 이어가다가 AI가 실제 수익을 창출하는 시점에 버티컬 사업으로 수익을 창출하려는 전략을 가지고 있다"고 말했다.
< 저작권자 ⓒ 자본시장 미디어 'thebell', 무단 전재, 재배포 및 AI학습 이용 금지 >

관련기사

best clicks
최신뉴스 in 전체기사
-
- [코스닥 상장사 매물 분석]새주인 들어선 SC엔지니어링, 이사진 대거 교체
- 'BBB급' 두산퓨얼셀, 차입금리 낮추기 집중
- [i-point]케이쓰리아이, 아시아 첫 '볼로냐 라가치 크로스미디어상'
- 글로벌사업 중심축 두산밥캣, '5세 경영수업' 무대됐다
- 이창용 한은 총재, '1%대 성장률' 지속 우려에 작심발언
- [thebell interview]"AI 핵심은 인프라SW…모레, 넥스트 딥시크 만들 것"
- [thebell interview]"크립톤, 'AC 이정표' 될 것…AUM 1000억 도전"
- [심플랫폼 Road to IPO]깐깐해진 시장 눈높이…'섹터 매력·공모액' 합격점
- [다시 돌아온 초록뱀 그룹]전방위 영토확장, 이번엔 가상자산 간접투자 단행
- 'EUV PR 국산화 큰별' 이부섭 동진쎄미켐 회장 별세
최윤신 기자의 다른 기사 보기
-
- [thebell interview]"AI 핵심은 인프라SW…모레, 넥스트 딥시크 만들 것"
- [VC 라운지 토크]김학균 협회장 시대, 주목받는 1972년생 네트워크
- [LP Radar]신협중앙회, 2대 1 숏리스트…대형펀드 결성 VC '우위'
- [thebell interview/LP Radar]"우리운용, 다양한 주체 이끄는 모험자본 '통로' 지향"
- '리퍼비시 커머스' 팜코브, 50억 시리즈A 본격화
- [LP Radar/thebell interview]"신한운용, 모펀드 강자 넘어 한국판 하버베스트 되겠다"
- SM컬처파트너스, '벤처투자회사'로 등록 배경은
- [2025 VC 로드맵]송영석 대표 "KB인베, 투자보다 회수액 많은 원년될것"
- 성장금융, CIO 연임 첫 사례 나올까
- [VC 투자기업]'미세조류 배양' 비루트랩, 프리시리즈A 유치 속도